
Hey! Stop Training Your LLM!
Is RAG your Fastest Path to ROI?

I know it’s been a long while since my last post, where we explored the often-overlooked environmental costs of training and maintaining colossal, generalized AI models. The conversation then centered on its hidden life-altering effects. Today, I want to dive into a different opportunity, a resource that is currently being overlooked: your company’s proprietary data.
The current enterprise landscape is defined by a paradox: a corporate rush to deploy the most complex, cutting-edge Foundation Models possible, often overlooking that the simplest, most efficient architectural pattern—the Agent System grounded in internal databases—offers the fastest, most measurable return on investment (ROI). This is the true enterprise imperative: shifting focus from expensive model training to high-impact, low-friction knowledge retrieval.
RAG Over Retraining
The primary bottleneck for most organizations is not the lack of a suitable Large Language Model (LLM)—the market is saturated with powerful, general-purpose engines. The constraint is the cost and complexity of making that engine trustworthy and relevant to a specialized corporate domain.
This is where the agent architecture, specifically one leveraging Retrieval-Augmented Generation (RAG), decisively wins the race for initial impact. The RAG Agent is not about altering the brain of the LLM through fine-tuning; it’s about providing it with an indispensable, real-time memory accessible at the moment of query.
In stark contrast to fine-tuning, which requires vast computational resources and specialized ML infrastructure to bake knowledge into the model’s parameters permanently, a process that often takes months and demands retraining every time proprietary knowledge changes, RAG implementation is comparatively lean.
The investment shifts from millions in GPU clusters and massive training cycles to engineering excellence in data ingestion and indexing. The architecture focuses on connecting the LLM to an external knowledge base—often a vector database of internal documents, policies, and records. This approach is inherently more resource-efficient:
Cost Efficiency: RAG is generally cheaper and faster to deploy than fine-tuning, as it avoids the massive computational cost of retraining the base model.
Time to Value: Organizations implementing AI agents focused on productivity report an average time-to-market from concept to production deployment between 3 and 6 months, with some mature solutions achieving full deployment in as little as 4–6 weeks.
This architectural pivot ensures that your system’s knowledge is dynamic, not static. When a policy changes or a new product is launched, you update the proprietary database, not the multi-billion parameter model. This drastically reduces the resource footprint associated with maintaining current information—a direct counterpoint to the “Hidden Environmental Resource Cost” we discussed previously.
The Proprietary Knowledge Multiplier
The critical value proposition of internal DB-grounded agents is the elevation of factual accuracy and the systemic mitigation of hallucination. A large, generalized LLM, when asked about your proprietary HR policy or a specific clause in a legacy contract, will inevitably default to confidence without context.
RAG Agents address this core enterprise risk by creating a verifiable feedback loop. In the simplest form, the agent executes a three-step critical workflow:
Retrieval: Using the user’s query, the agent performs a semantic search against the internal knowledge base (database, data lake, wiki).
Augmentation: It retrieves the most relevant proprietary snippets and wraps them with the user’s query and instructions for the LLM.
Generation: The LLM generates the response, explicitly grounded in the retrieved company facts, often including citations back to the source document.
This ability to provide real-time, verifiable context, which often includes access control measures to maintain data privacy, is why RAG agents are quickly becoming the “go-to architecture for building enterprise-grade AI applications.” The model is suddenly trustworthy because its output is auditable.
Corporate Adoption: RAG for Trust, Fine-Tuning for Tone
While the majority of enterprise use cases benefit most from the efficiency and verifiability of RAG, it is crucial to understand why certain top-tier companies adopt one over the other, or a hybrid approach. The distinction often comes down to the core necessity: Trust (RAG) versus Tone (Fine-Tuning).
The RAG Dominance: Grounding Knowledge and Compliance
Top-tier companies in regulated and knowledge-intensive sectors heavily favor RAG architectures because they require auditability and proprietary context.
Financial Services (e.g., JPMorgan Chase, Goldman Sachs): These institutions are implementing agent systems to answer complex queries regarding internal risk frameworks, compliance regulations (e.g., AML, KYC), and legacy system documentation. They use RAG because accuracy and the ability to cite the source document are non-negotiable legal requirements. Fine-tuning, which blends the source data into the model weights, makes traceability impossible.
Consulting & Professional Services (e.g., McKinsey & Co., Deloitte): These firms rely on massive, constantly evolving internal knowledge bases—years of proprietary case studies, client deliverables, and best practices. They use RAG to power internal research agents that instantly synthesize decades of proprietary data for new client pitches and strategies. The efficiency gain is immediate, as RAG deployment is faster than the model-centric alternative.
Enterprise Software (e.g., Microsoft, Salesforce): Companies with vast product documentation and complex APIs deploy RAG-backed agents to power internal and external support systems. They use RAG to ensure the agent’s answers reflect the very latest product changes and documentation updates without incurring the environmental and operational cost of retraining large models weekly.
The Fine-Tuning Niche: Customizing Persona and Style
Fine-Tuning (FT), while expensive and resource-heavy, still holds strategic value for companies whose primary goal is not factual knowledge but brand voice, tone, and specific behavioral customization.
Media & Entertainment (e.g., News Publishers, Creative Agencies): These companies may fine-tune smaller, domain-specific models to adopt a unique journalistic style, narrative voice, or specific creative constraints (e.g., only writing in sonnets, or only summarizing articles with a sarcastic tone). They use FT because RAG cannot fundamentally change the model’s output style; it only changes its facts.
High-Volume Consumer Bots (Internal): While most consumer bots use RAG for facts, internal service operations might fine-tune a model’s ‘personality’ layer to ensure it strictly follows a specific internal workflow protocol (e.g., always asking for the case number first, or strictly adhering to internal safety classification criteria).
The overarching lesson remains: most high-impact, enterprise use cases—those designed to automate back-office knowledge work, compliance, and internal support are data-centric and best served by the resource-frugal RAG Agent architecture.
Case Velocity: Quantifiable Impact and Real Data
The efficacy of RAG agents is not theoretical; it is measured in immediate, quantifiable enterprise metrics across diverse sectors. Executives are not waiting years for ambiguous gains; they are seeing payback in the space of a single fiscal quarter.
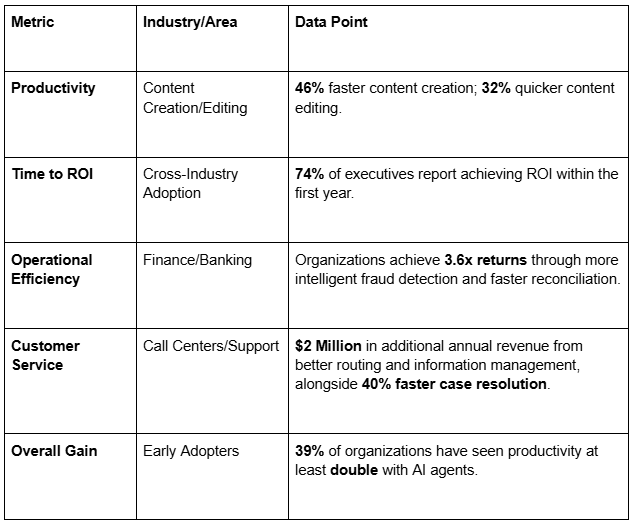
These stats show a clear trend: the highest initial value is derived from applying AI not to novel creative tasks, but to the mundane, high-volume, knowledge-intensive workflows that choke existing personnel.
Consider the Compliance Agent in a financial institution. Instead of forcing human staff to spend hours cross-referencing evolving regulatory documentation (which constantly changes, making Fine-Tuning impractical) against internal operating procedures, an agent can instantly retrieve and harmonize the relevant passages. This is not automation for the sake of novelty; it is hyper-specific operational leverage that dramatically reduces regulatory risk and frees up expert hours for strategic work.
Redirection: Focus on the Core Asset
The true lesson here is that complexity is the enemy of velocity. For most enterprises, the fastest path to significant, measurable value—the path with the least resource drain and most up-front impact is to bypass the billion-parameter training competition entirely.
Instead, the simplest, most effective AI solution lies in treating your accumulated proprietary data—your internal databases, documents, and institutional memory—as the most valuable LLM training input available. By packaging this knowledge within a RAG-powered agent system, organizations deliver an AI that is grounded, current, and auditable, generating immediate business returns and transforming operational efficiency in a timeframe the custom-model approach simply cannot match. The fastest wins in AI are almost always data problems, not model problems.
© sayheyrey.com 2025 - All Rights Reserved